Blog, 2016 Blogs
RLCatalyst Pulse
As enterprises have to deal with large amount of data, there evolved a need to find a better solution to keep and analyse many types of data, that eliminates the challenges posed by big data. The concept of Data Lake thus emerged, that can deal with all types of data needed to be captured and exploited by enterprises. Though data lake was tied to Apache Hadoop system initially, as enterprises got to see definite business value-add, they started creating data lakes to complement their data warehouses.
Data Lake caters to the following needs:
1. Store raw data at a low cost
2. Stores both structured and unstructured data in the same repository
3. Perform data transformations and analytics
As IT organizations are extending Agile and DevOps to make the delivery faster, the need for collaborating information from multiple sources is also growing. The source can be a DevOps tool, or a CMDB or a cloud provider. RLCatalyst is solving this by its data lake called ‘RLCatalyst Pulse’
Pulse is designed to collect data from different sources at a regular interval to get the near-real time information. The collectors will load the data lake, which will later be aggregated as per the specific requirements. The visualization layer will consume this data and will send to various portals .
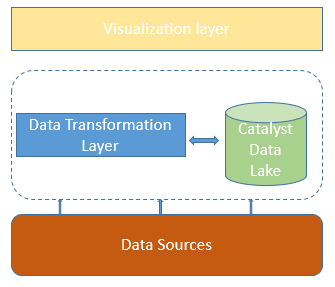
The data lake caters to various dashboards like – Assets Tracking, Project Management, Release Management, Build/Deployment dashboard, QA dashboard, Dev dashboard and an end-to-end Operations dashboards. This gives a 360 degree view of your Assets and Process Management. Enterprises in which the assets are allocated across different teams without proper tracking, can benefit from Catalyst Pulse, as it gives a report on the phantom capacity, thereby giving a clear picture on what is utilized/underutilized. This is being extended to build self-aware elements that can take automatic corrective actions by analyzing various metrics available in data lake.


