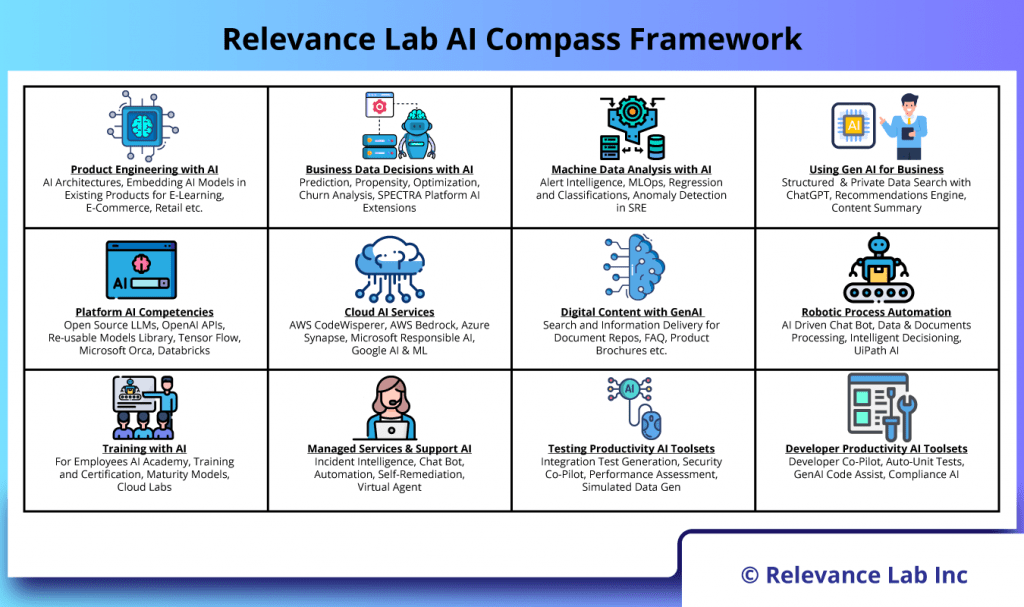
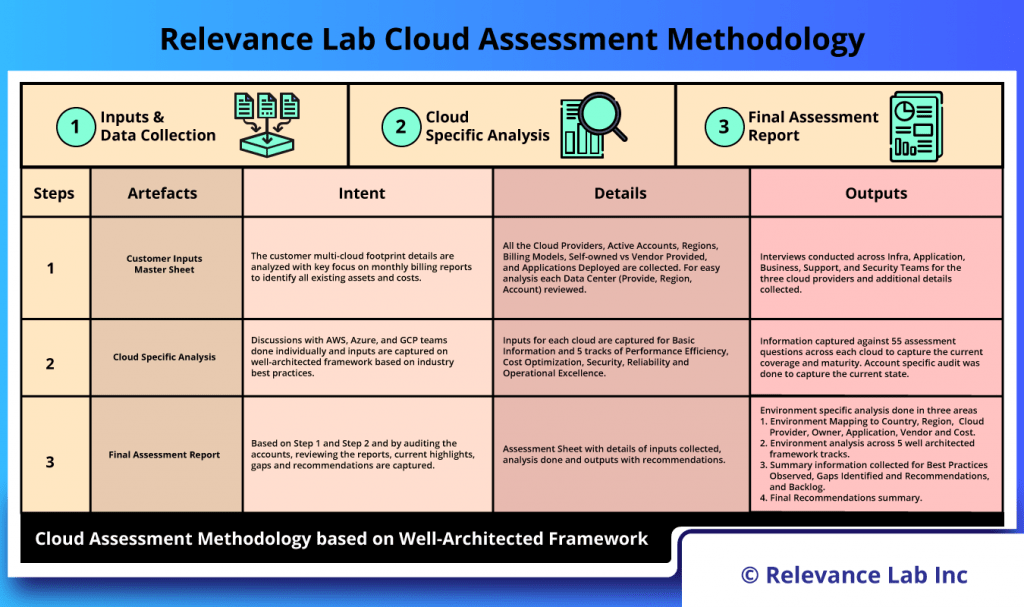
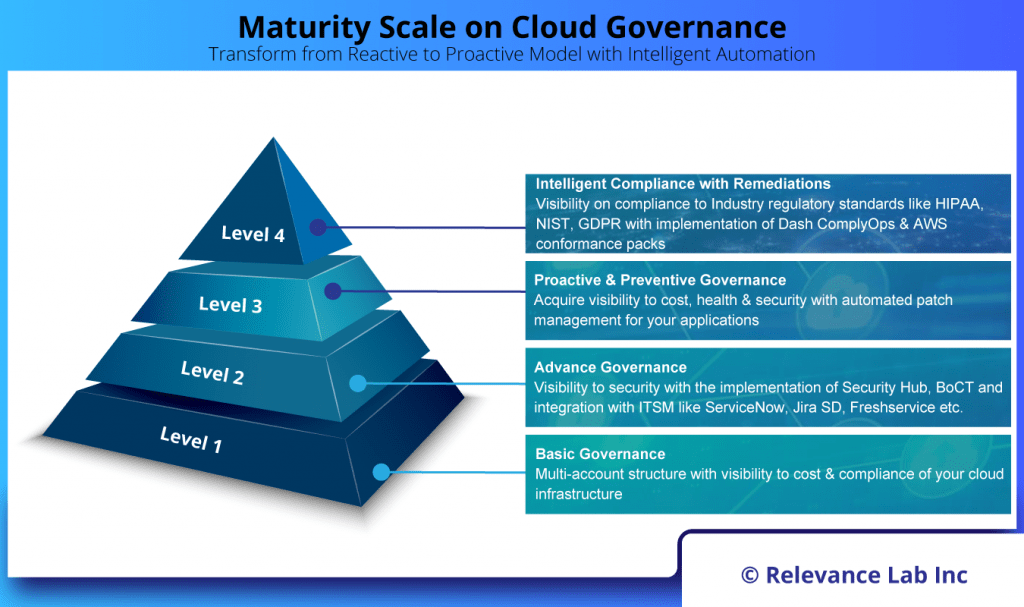
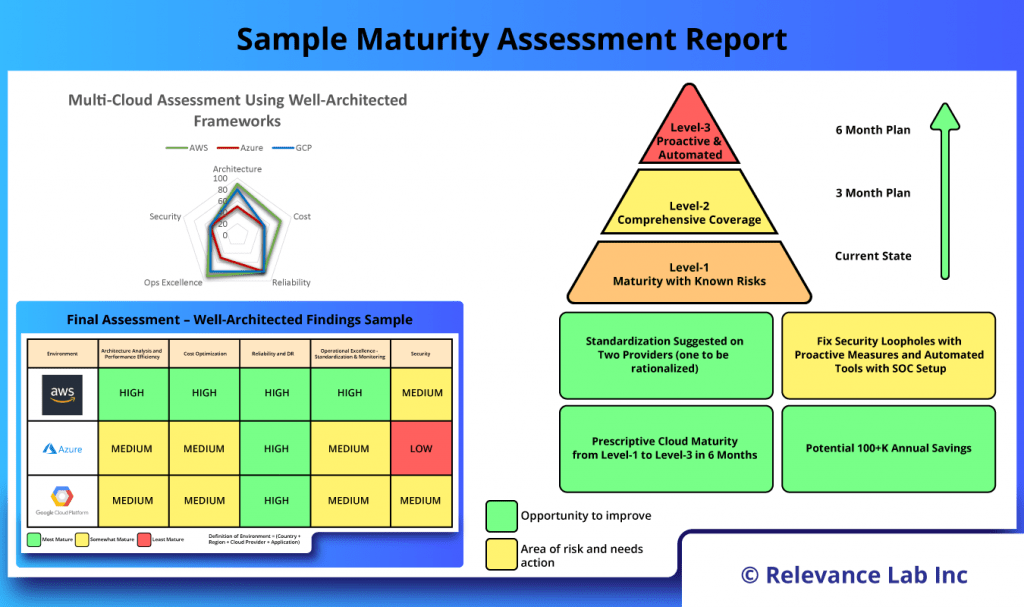
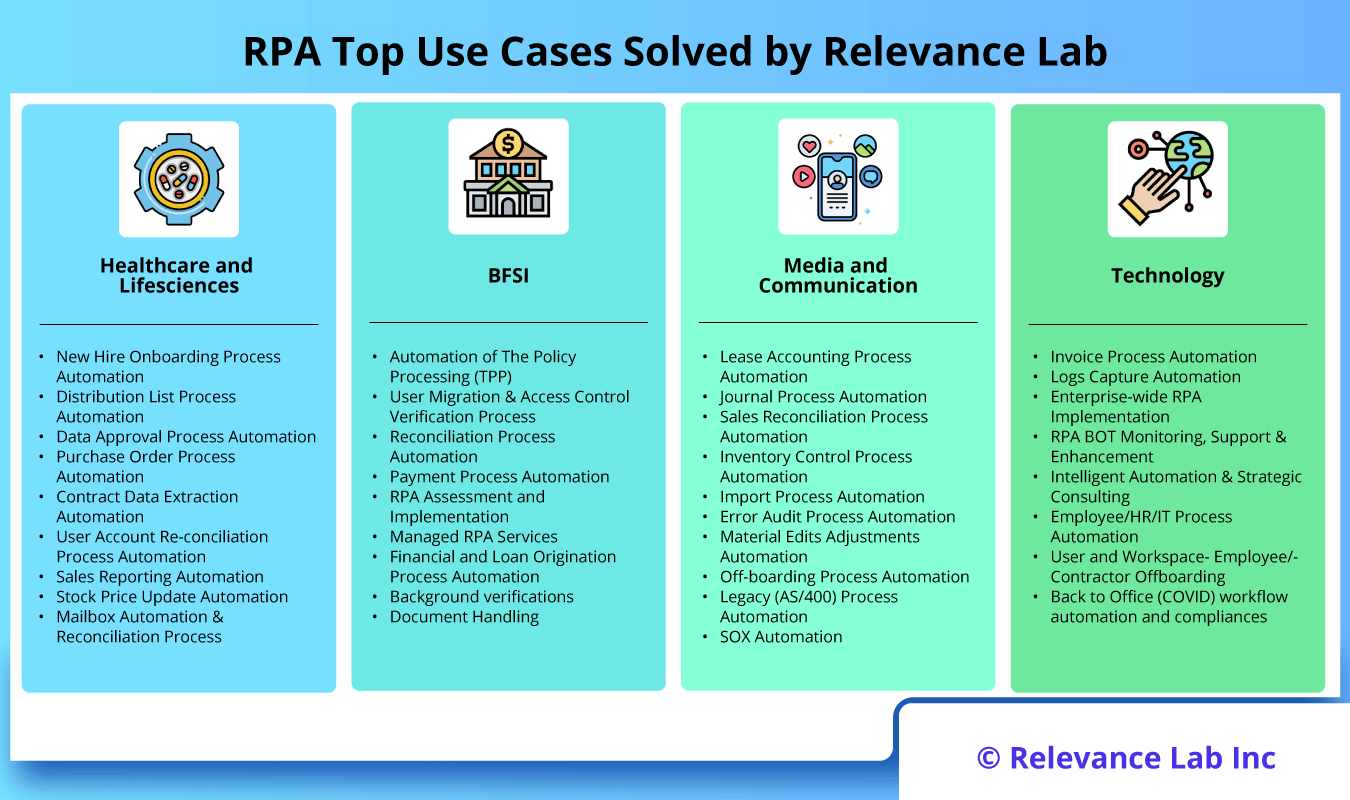
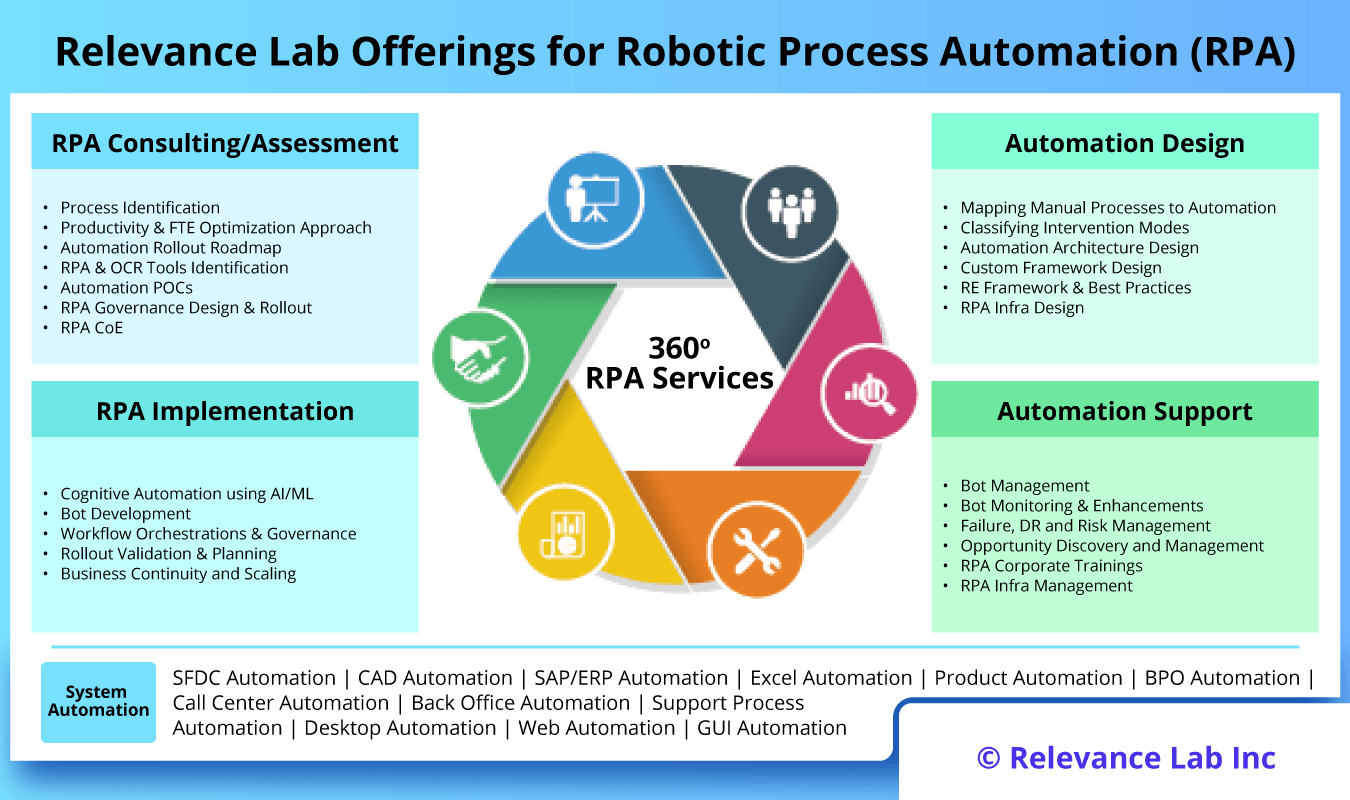
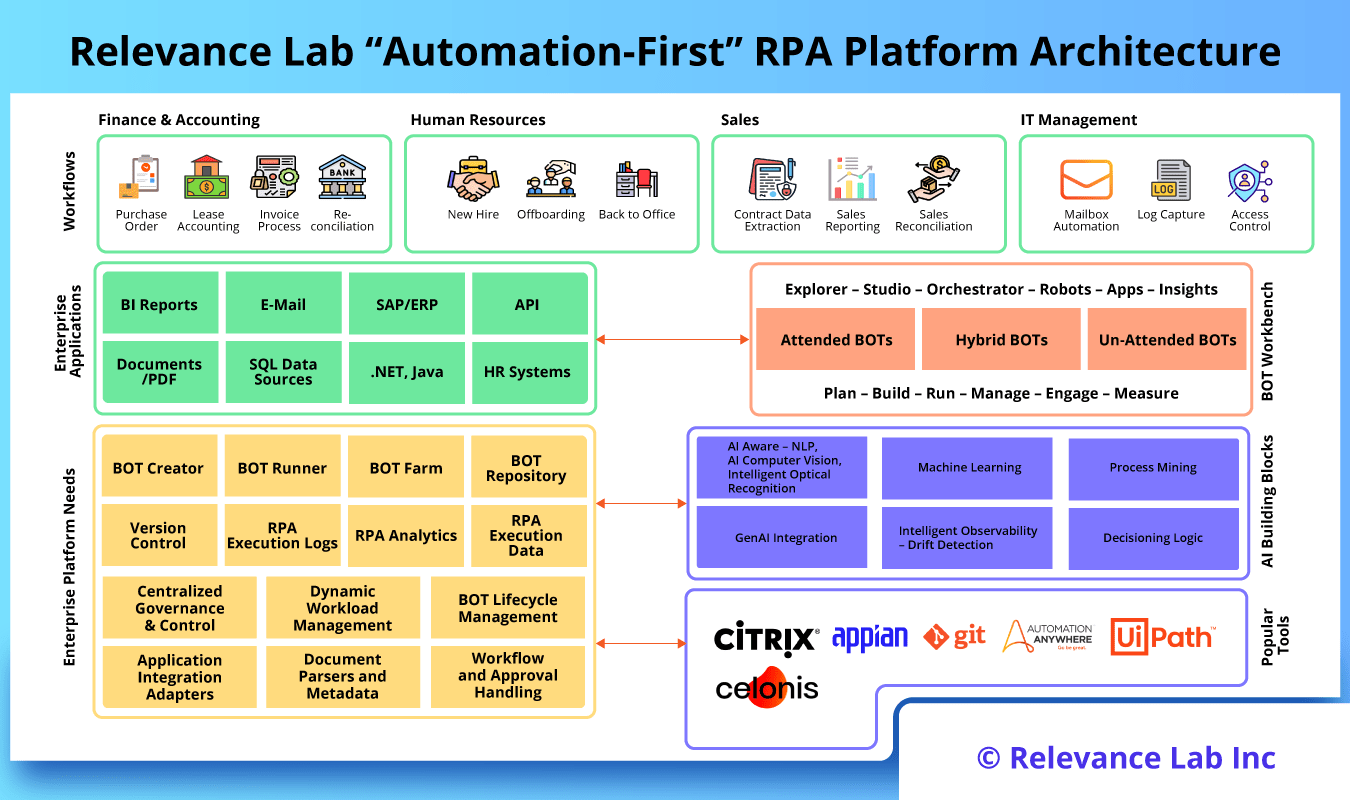
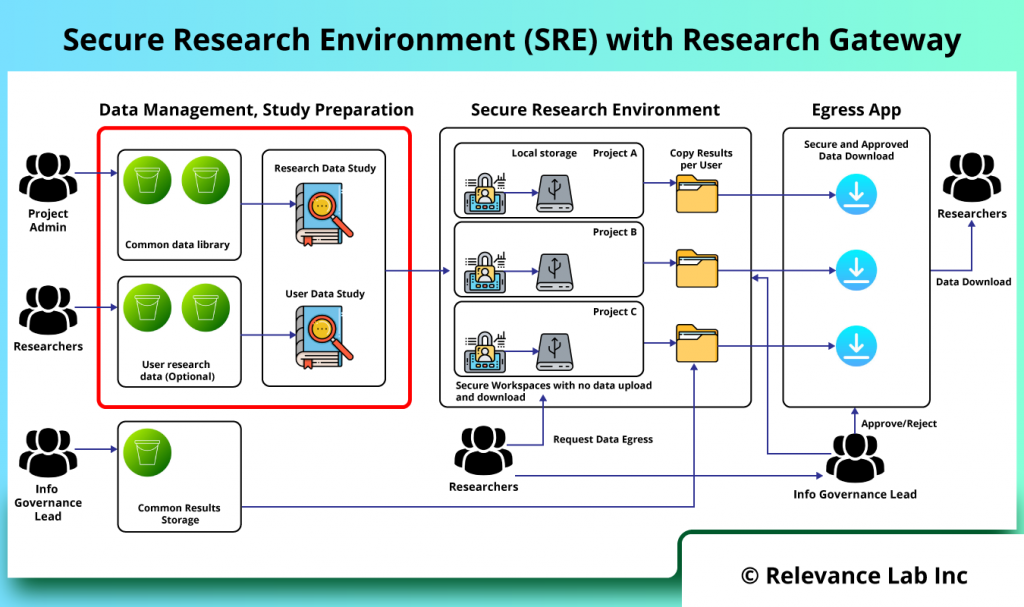
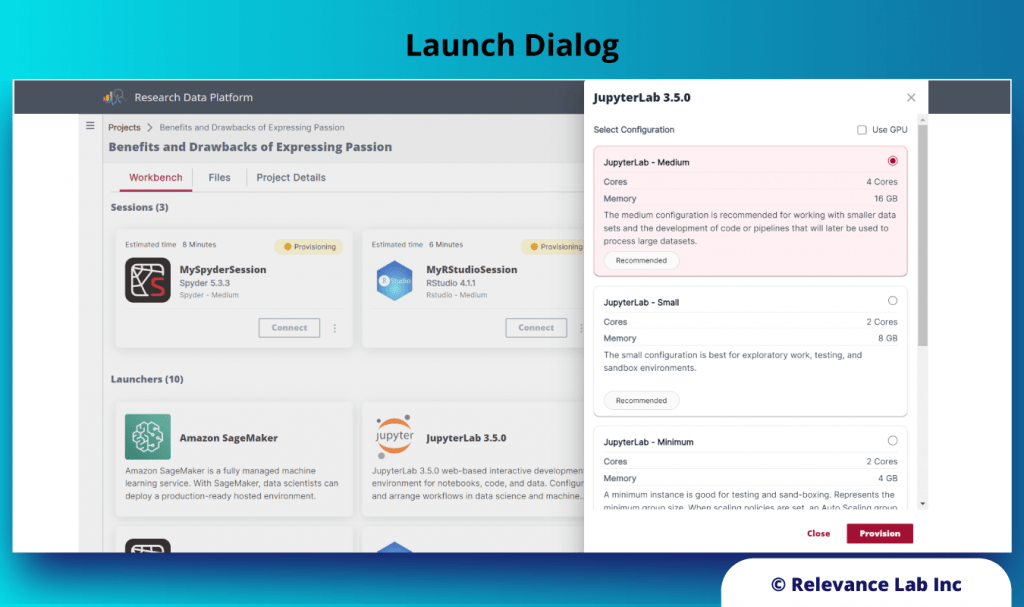
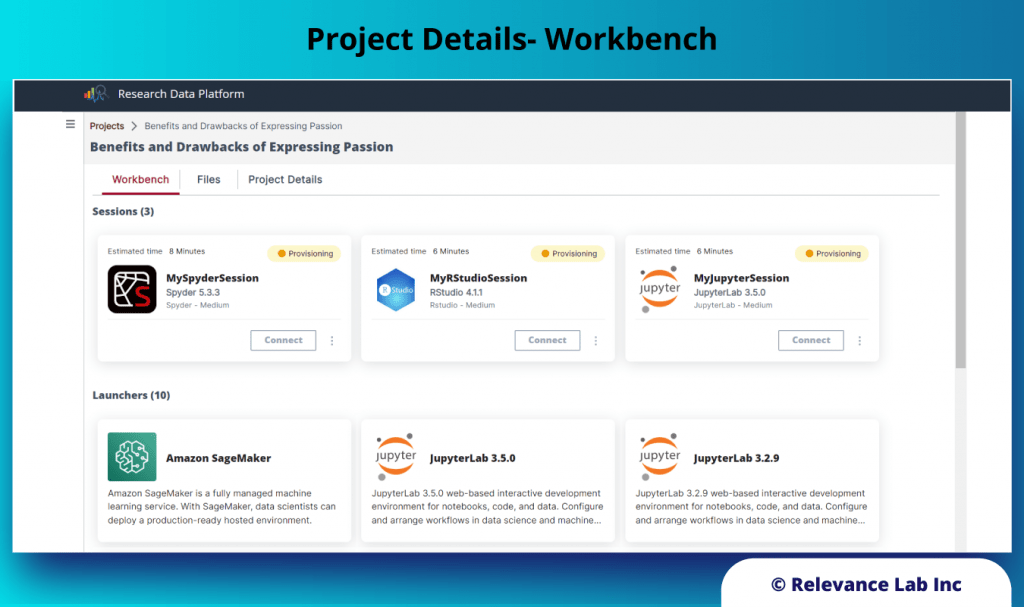
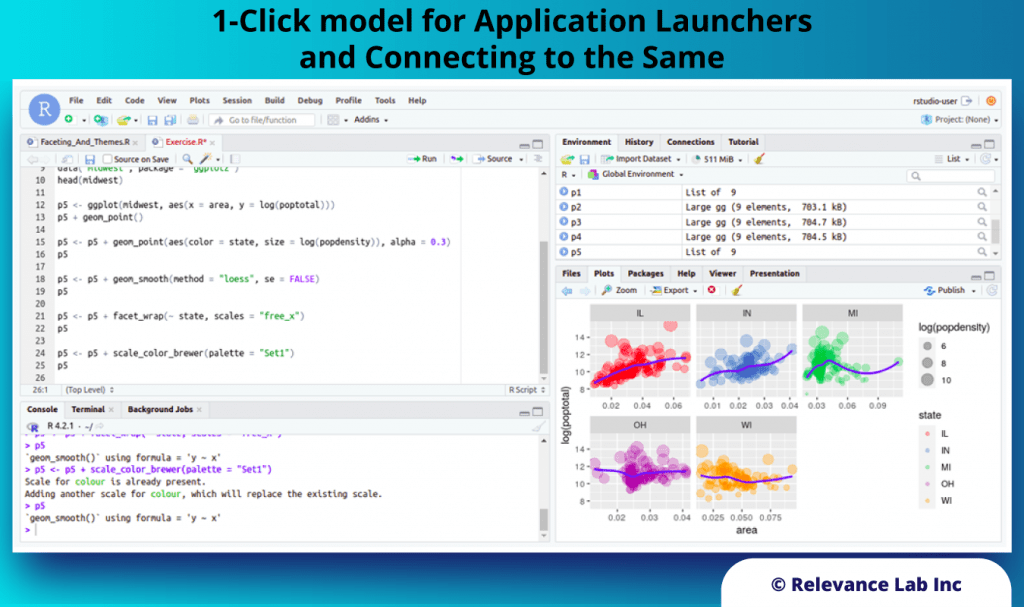
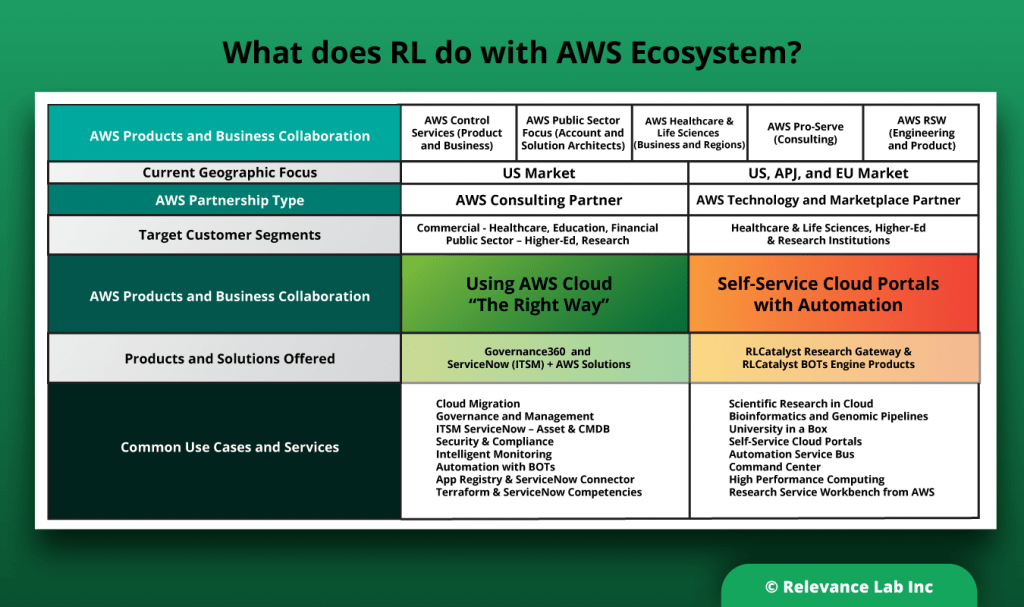
2024 Blog, Blog, Featured
With growing complexity across Cloud Infrastructure, Applications deployments, and Data pipelines there is a critical need for effective Site Reliability Engineering (SRE) solutions for large enterprises. While this is a common need, the approach many companies seem to be attempting is solving the problem with multiple siloed efforts. Following are some common problems we have observed:
- Data Center oriented approach to solving SRE adoption with a focus on different layers across Storage, Compute, Network, Apps, and Databases. This approach creates silos with different teams working across the tracks.
- Significant focus on reactive models for Observability with multiple tools and overlapping monitoring coverage across on-prem & cloud systems. This creates alerts fatigue, false alarms, long diagnostics time, and slow recovery cycles.
- Long planning and analysis cycles on defining how to get started on “SRE Transformation Program” with multiple groups, approaches, and discovery cycles.
- Need for Organization clarity on who should drive SRE program across Infra, Apps, DevOps, Data and Service Delivery groups.
- Undefined roadmap for maturity and how to leverage Cloud, Automation, and AIOps to roll-out SRE programs at scale across the enterprise.
- Federated models of IT and Business Units with shared responsibility across global operations and how to balance the need for standardization vs self-service flexibility.
- Missing information on current problems and faults affecting end users with slow response times, surprise outages, unpredictable performance, and view on real time Business Performance Metrics (SLAs).
- Lack of mature Critical Incident Management and Incident Intelligence.
- Custom approach to solutions lacking ability to build a common framework and scale across different units.
- Need for Machine Learning Observability including data collection and alerting, additional data growth, data drift and consumption monitoring.
- Tracking Platform Cost visibility across business, regions, and projects.
With a growing Cloud footprint adoption, these issues have got amplified along with concerns on costs and security in the absence of mature SRE models slowing down digital transformation efforts.
To fix these issues in a prescriptive manner, Relevance Lab has worked with some large customers to evolve a “Platform Centric” model to SRE adoption. This leverages common tools and open-source technologies that can speed up SRE implementation by saving significant time, cost, and efforts. Also, with a rapid deployment model the rollout can be done across a global enterprise with Automation driven templates.
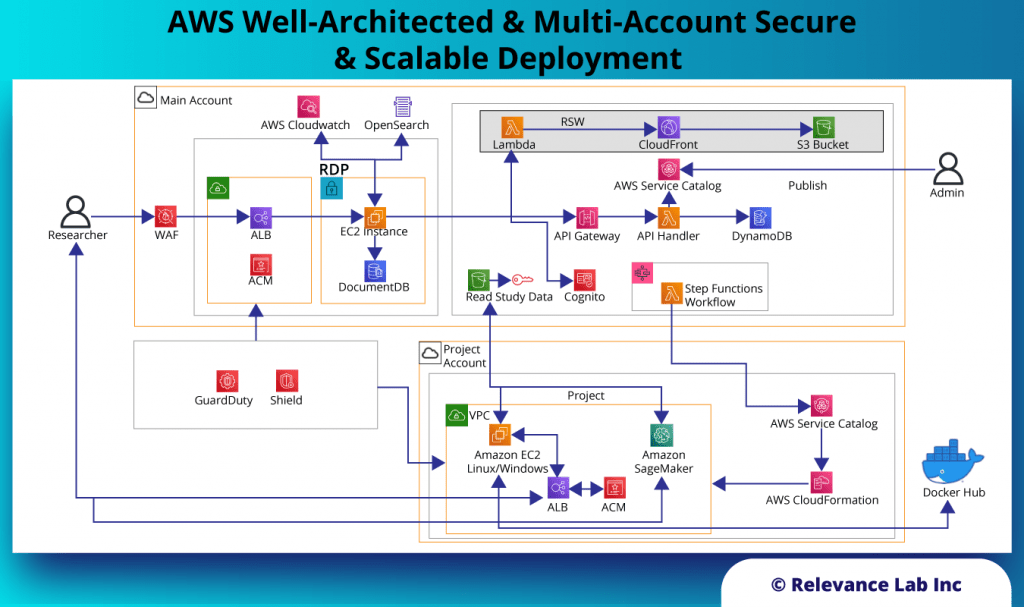
The figure below explains the Command Centre SRE Platform from Relevance Lab.
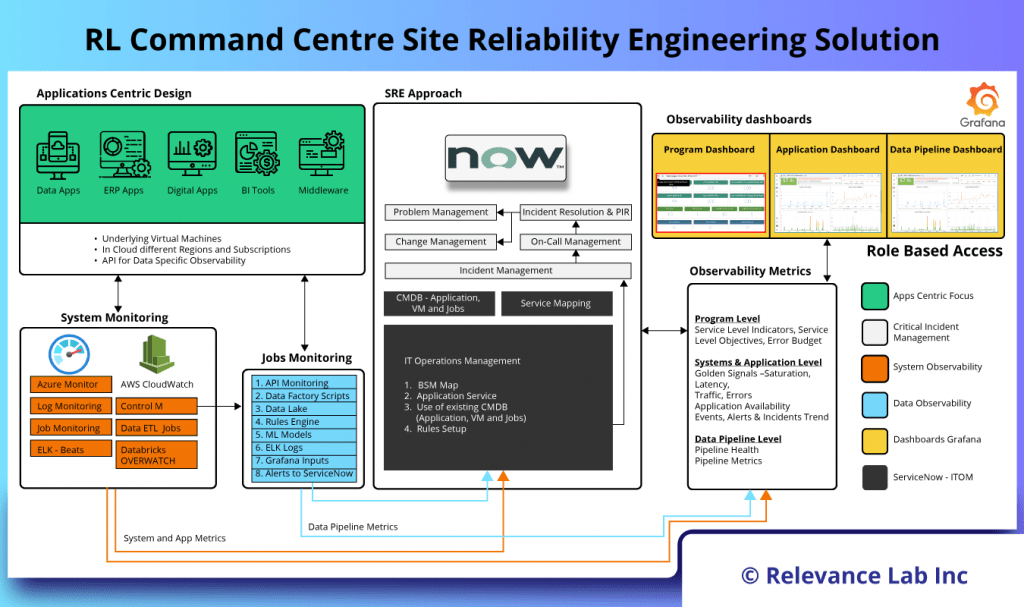
Building Blocks of SRE Platform
- Application Centric Design
- The first step towards building a mature SRE implementation starts with an application centric view aligned to business services. By using platforms like ServiceNow, we can build relationships or service maps between Infrastructure and application services. This is crucial and helps during an outage in identification of root cause.
- Once all assets are identified, segregated based on type of applications, business services tagged and managed centrally.
- Monitoring
- The next step is to have monitoring sensors enabled for all business-critical systems. Enablement of monitoring sensors could vary based on the type of resources as mentioned below:
- Systems Monitoring: This is typically Infrastructure and Network monitoring and could be enabled either using the native cloud services or using third party tools like AWS CloudWatch, Azure Monitor, Solarwinds, Zabbix etc.
- Applications or Logs Monitoring: Application monitoring involves both performance monitoring as well as logs monitoring, this can also be achieved using the cloud native tools or third-party tools like AppDynamics, ELK, Splunk, AWS X-ray, Azure application insights etc.
- Jobs Monitoring: For monitoring scheduled jobs, tools like NewRelic, Dynatrace, Control-M etc, are used.
- SRE Approach with Event Management
- Now that the monitoring sensors are enabled, this will generate a lot of alerts and most of this would be noise including false alarms and duplicate alerts. Relevance Lab algorithms help de-duplication, alert aggregation, and alert correlation of these alerts and thereby reduce alert fatigue.
- Golden Signals: The golden signals namely latency, traffic, errors, and saturation are defined, configured and setup for any abnormalities during this stage. By integrating these with the standard Incident Management and Problem Management process and ITSM Platforms, the application stability and reliability becomes matured over time.
- Observability Dashboards: Having a single pane of glass view across your environment gives you visibility of your Business Apps. Relevance Lab SRE implementation involves below dashboard as a standard out of box.
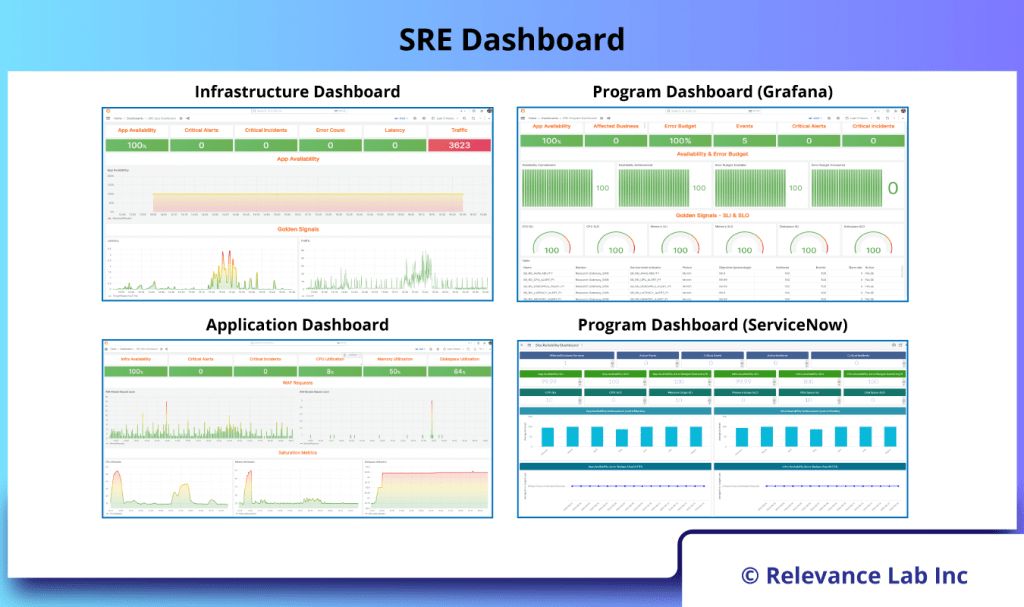
- Infrastructure Dashboard
- Application Dashboard
- Program Dashboard (Grafana)
- Program Dashboard (ServiceNow)
The figure below shows the SRE Dashboard in detail.
How can new customers benefit from our SRE Platform?
In today’s fast-paced and technology-driven world, organizations need robust and efficient IT operations to stay ahead of the competition. Relevance Lab’s SRE solution provides the necessary tools and frameworks to unlock operational excellence, ensuring high availability, scalability, and reliability of critical business systems. With our SRE solution, organizations can focus on innovation and growth, confident in the knowledge that their IT infrastructure is well-managed and optimized for exceptional performance.
Summary
Relevance Lab is a specialist in SRE implementation and helps organizations achieve reliability and stability with SRE execution. While Enterprises can try and build some of these solutions, it is a time-consuming activity and error-prone and needs a specialist partner. We realize that each large enterprise has a different context-culture-constraint model covering organization structures, team skills/maturity, technology, and processes. Hence the right model for any organization will have to be created as a collaborative model, where Relevance Lab will act as an advisor to Plan, Build and Run the SRE model.
For more details, please feel free to reach out to marketing@relevancelab.com
References
Site Reliability Engineering Ensures Digital Transformation Promises are Delivered to End-Users
What is Site Reliability Engineering (SRE) – Google Definition?
Site reliability engineering documentation