

Over the last few years, many organizations have adopted AWS ParallelCluster to bring HPC workloads to the cloud. It provided flexibility, Slurm-based scheduling, and infrastructure control.
But as HPC usage matures—especially with AI, simulation, and large-scale analytics—organizations are hitting a common wall:
They don’t want to manage HPC infrastructure anymore.
This is where AWS Parallel Computing Service (PCS) comes in—offering a fully managed HPC control plane and eliminating the need to operate Slurm, scheduler HA, and cluster lifecycle manually.
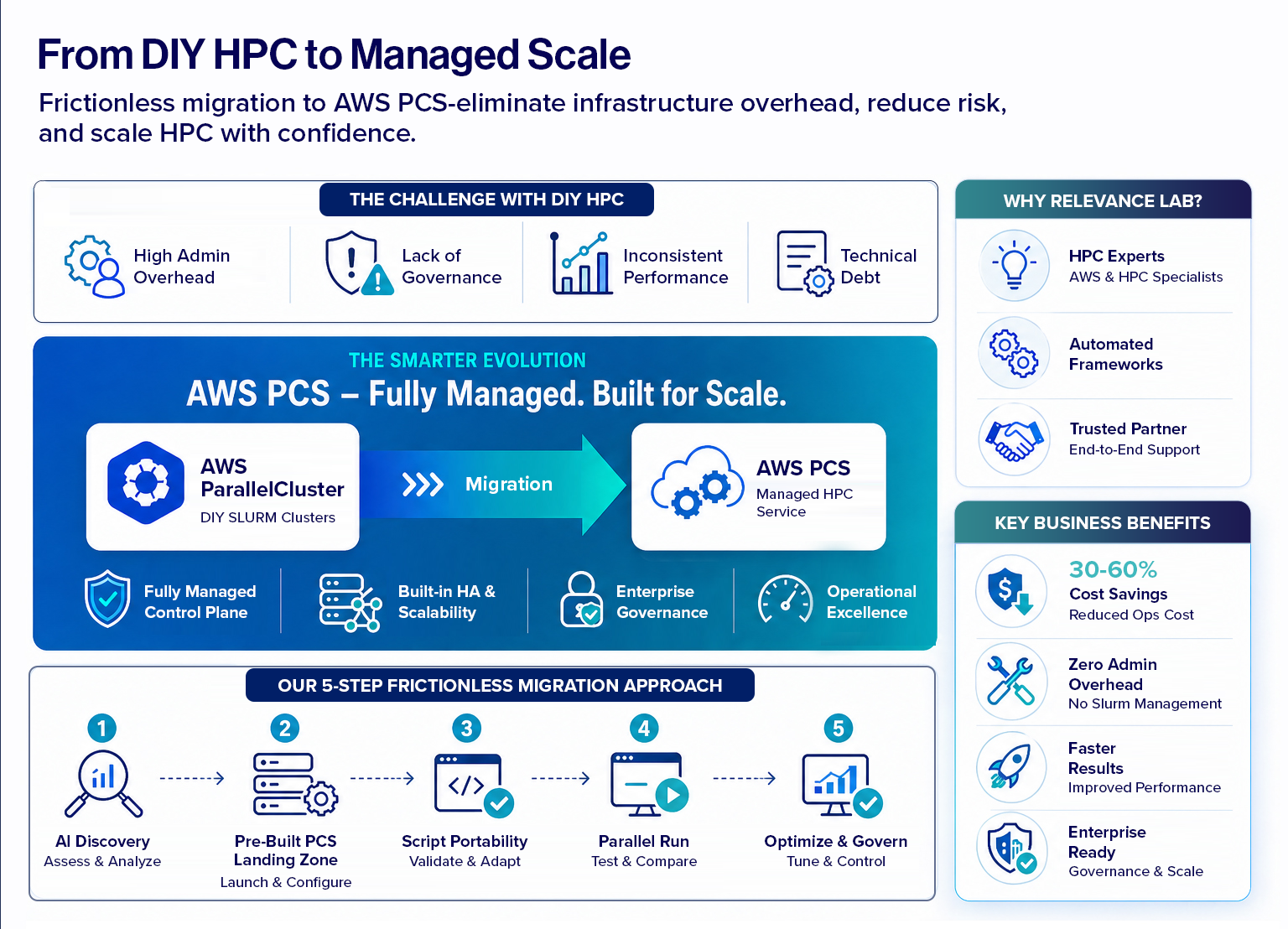
The Business Problem: Hidden Complexity Behind HPC
While ParallelCluster works well initially, enterprise teams face growing friction over time:
1. Operational Overhead
- Managing Slurm controllers, scaling, and failures
- Debugging cluster behavior and job scheduling issues
- Dependency on a few HPC admins
2. Lack of Governance
- Difficulty enforcing cost controls and queue policies
- Limited visibility across users and workloads
3. Inconsistent User Experience
- Queue unpredictability
- Performance variability
- Manual intervention for scaling or failures
4. Growing Technical Debt
- Custom scripts, prolog/epilog hacks
- Undocumented cluster behavior
- Hard-to-upgrade environments
Why AWS PCS is the Right Evolution
PCS represents a fundamental shift:
What This Means for Customers
- No more managing the Slurm control plane
- Reduced operational cost and risk
- Predictable, scalable HPC experience
- Platform ready for AI, GPU, and future workloads
The Real Challenge: Migration Isn’t Just Lift-and-Shift
Despite the benefits, migrating to PCS is not trivial.
Organizations often underestimate:
- Slurm customization dependencies
- Identity and access model differences
- Storage and data permission complexities
- Job script assumptions tied to cluster setup
PCS is not ParallelCluster v2—it is a different operating model.
Relevance Lab’s Solution: Frictionless Migration Framework
1. AI-Powered Discovery & Assessment
We start with an automated discovery framework that scans your existing environment:
- Slurm configurations and partitions
- Job script patterns and dependencies
- User, IAM, and access models
- Storage and data usage patterns
Output:
- Migration complexity score (Small / Medium / Large)
- Risk heatmap
- “What will break in PCS” insights
2. Pre-Built PCS Landing Zone
Instead of building from scratch, we use a pre-engineered PCS framework:
- Standard queue design (CPU / GPU / priority tiers)
- Integrated identity and access patterns
- Storage and mount standardization
- Monitoring and observability built-in
Result:
- Faster deployment
- Reduced design errors
- Enterprise-ready from Day 1
3. Job Script Compatibility Layer
“Do we need to rewrite our jobs?”
Answer: No.
- 90–95% of Slurm job scripts work as-is
- We map partitions → PCS queues
- Normalize scripts to remove cluster-specific assumptions
- Provide ready-to-use job templates
Outcome:
- Minimal user disruption
- Faster adoption
4. Parallel Run & Controlled Cutover
We ensure a zero-risk transition:
- Run ParallelCluster and PCS side-by-side
- Validate real workloads
- Compare performance and outputs
- Execute phased cutover
No surprises in production
5. Optimization & Governance
Migration is just the beginning.
We help customers:
- Optimize queue configurations
- Improve cost efficiency
- Implement governance and chargeback
- Enable self-service HPC
Business Benefits of the Migration
Definition of Success
A successful migration is not just technical—it’s operational and business-driven:
- Jobs run without modification
- Users experience no disruption
- No need to manage Slurm manually
- ParallelCluster can be safely decommissioned
- Platform is ready for future AI and HPC workloads
Why Relevance Lab?
- Deep expertise in AWS HPC and cloud platforms
- Proven migration methodology
- Automation-first approach
- Pre-built frameworks to accelerate delivery
We don’t just migrate clusters—we modernize HPC platforms.
Final Thought
As organizations scale AI and HPC workloads, the question is no longer:
“Can we manage HPC ourselves?”
It becomes:
“Why should we?”
With AWS PCS and Relevance Lab’s Frictionless Migration Framework, you can move from DIY infrastructure to a fully managed HPC platform—faster, safer, and with measurable ROI.