

Across leading universities and research institutions, a profound shift is underway.
Artificial Intelligence, especially Generative AI is no longer a niche capability confined to select labs. It is rapidly becoming the core engine of research, innovation, and academic competitiveness. From large language models (LLMs) and multimodal AI to simulation-driven discovery, compute-intensive AI workloads are exploding in scale and complexity.
Yet, while demand accelerates, institutional infrastructure struggles to keep pace.
This has created a defining challenge for higher-ed leaders:
How do you build an AI platform that is scalable, cost-effective, secure, and easy for researchers to use without fragmenting the experience?
The Higher-Ed Dilemma: Three Forces in Conflict
Most institutions today find themselves navigating three competing priorities:
1. On-Premises AI Cloud Investments
On-prem infrastructure remains essential for:
- Sensitive and regulated datasets
- Low-latency HPC workloads
- Predictable baseline utilization
However, it comes with:
- High capital expenditure
- Rapid GPU obsolescence cycles
- Limited elasticity for peak demand
2. Public Cloud Acceleration with AWS
Cloud platforms like Amazon Web Services offer:
- On-demand access to cutting-edge GPUs
- Elastic scaling for burst workloads
- Managed AI services and rapid innovation
But introduce:
- Cost management challenges
- Governance and compliance concerns
- Data gravity and transfer complexities
3. Fragmented Research Experience
Researchers often face:
- Multiple systems (HPC portals, Kubernetes dashboards, cloud consoles)
- Complex provisioning workflows
- Limited visibility into costs and usage
The result: infrastructure exists—but productivity suffers.
Understanding GenAI Workloads: Two Worlds, One Platform
A critical insight often overlooked is that GenAI workloads are not uniform. They fall into two distinct execution paradigms:
1. LLM Training: HPC-Centric Workloads
Training large models requires:
- Distributed, multi-node GPU clusters
- Batch scheduling systems like Slurm
- High-performance storage and networking
Typical stack:
- Slurm scheduler
- Open OnDemand (OOD) for access
- Parallel file systems
Use cases:
- Foundation model training
- Fine-tuning at scale
- Simulation + AI convergence
2. LLM Serving & AI Applications: Kubernetes-Centric Workloads
Serving and application layers require:
- Interactive environments
- API-driven microservices
- Elastic scaling
Typical stack:
- Kubernetes (on-prem or cloud)
- JupyterHub / VSCode access
- LLM serving frameworks (vLLM, Triton, Ray Serve)
Use cases:
- Chatbots and copilots
- Retrieval-Augmented Generation (RAG)
- AI agents and applications
The Core Problem: Disconnected Platforms
In most institutions:
- HPC environments operate in isolation
- Kubernetes-based AI platforms are separate
- Public cloud adds a third silo
This fragmentation leads to:
- Poor utilization of resources
- Increased operational overhead
- Lack of unified governance and cost control
The Shift: Toward a Unified Hybrid AI Cloud
Forward-looking institutions are adopting a new principle:
HPC and Kubernetes are not competing platforms—they are complementary execution engines.
The goal is to unify them under:
- A common control plane
- A shared data strategy
- A seamless user experience
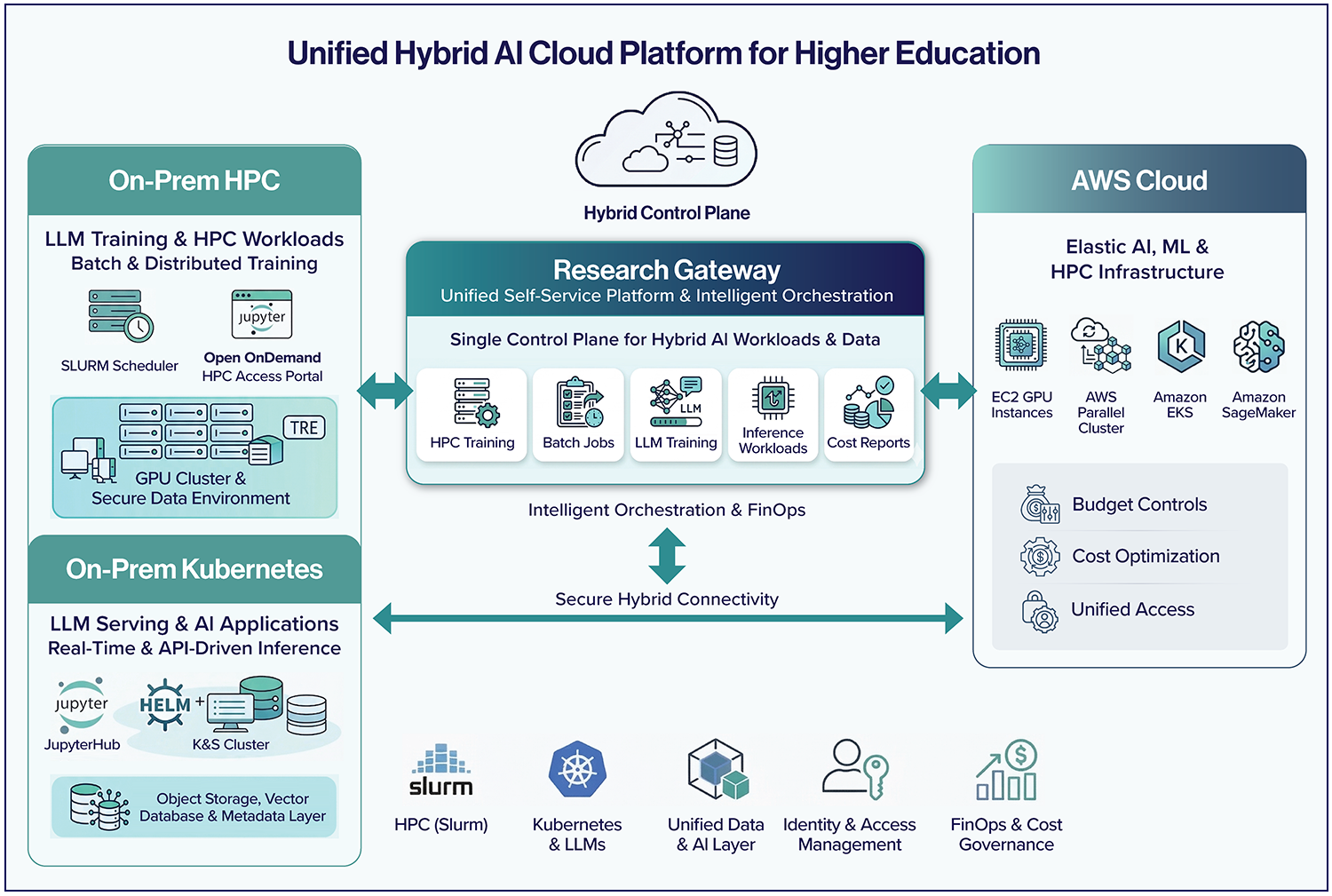
The AWS + Relevance Lab Approach
Relevance Lab, in partnership with AWS, provides a prescriptive hybrid AI cloud model tailored for higher education.
1. Dual-Platform AI Cloud (On-Prem Foundation)
Institutions establish:
- HPC layer: Slurm + OOD for training workloads
- Kubernetes layer: GPU-enabled clusters for AI applications
- Shared data layer: File systems, object storage, vector databases
- Unified identity: Enterprise IAM integration
2. Seamless Cloud Extension on AWS
AWS acts as a natural extension of on-prem infrastructure:
Compute:
- HPC burst via AWS Parallel Cluster
- Kubernetes extension via Amazon EKS
Data:
- FSx for Lustre integrated with Amazon S3
- Intelligent caching and data locality strategies
Access:
- Federated identity across environments
FinOps:
- Budget-aware bursting
- Cost attribution by project and grant
The Missing Layer: Orchestration and Experience
Despite strong infrastructure, many hybrid strategies fail due to one gap:
Lack of a unified orchestration and self-service layer
Research Gateway: The Unified AI Platform Experience
Research Gateway (RG) from Relevance Lab acts as the central control plane.
1. Single Self-Service Portal
Researchers can:
- Launch Jupyter notebooks, HPC jobs, or AI environments
- Select workload types (training, inference, analysis)
- Avoid infrastructure complexity entirely
2. Integration with Existing Ecosystems
RG enhances—not replaces—existing investments:
- Open OnDemand (HPC access)
- JupyterHub (interactive environments)
- VSCode, RStudio
3. Intelligent Workload Orchestration
RG automatically determines:
- HPC vs Kubernetes
- On-Prem vs AWS
Based on:
- Data sensitivity
- GPU availability
- Cost policies
- Performance requirements
4. Built-in Governance and Security
- Role-based access control
- Secure environment templates (including TREs)
- Policy-driven provisioning
5. Embedded FinOps
- Real-time cost visibility
- Budget enforcement
- Chargeback by department, project, or grant
End-to-End Workflow: A Seamless Research Experience
- Researcher logs into Research Gateway
- Selects workload type (e.g., “Train Model” or “Deploy Application”)
- Platform automatically provisions resources
- Workload executes on optimal environment (on-prem or AWS)
- Costs and usage are tracked transparently
Why This Matters: Outcomes That Transform Research
Institutions adopting this model achieve:
- Accelerated research cycles through frictionless access
- Optimized costs with intelligent workload placement
- Improved governance without slowing innovation
- Future-ready platforms for LLMs, agents, and beyond
Why AWS + Relevance Lab
AWS
- Industry-leading AI and HPC infrastructure
- Elastic scalability and global reach
- Continuous innovation in AI services
Relevance Lab
- Deep expertise in hybrid cloud and research environments
- Proven Research Gateway platform
- Strong focus on FinOps and governance
Conclusion: Building the AI Research Platform of the Future
The next decade of research will not be defined by isolated infrastructure investments, but by integrated, intelligent platforms.
The winners will not be those with the most GPUs but those who make AI accessible, governed, and scalable for every researcher.
With AWS + Relevance Lab + Research Gateway, institutions can move beyond the dilemma and build a unified Hybrid AI Cloud platform ready for the future of research.