

Generative AI is reshaping how organizations work, research, and innovate. From summarizing complex documents to accelerating coding, improving knowledge discovery, and enabling natural language access to information, the benefits are clear.
Yet for institutions operating in highly regulated or privacy-sensitive environments, adoption is not straightforward.
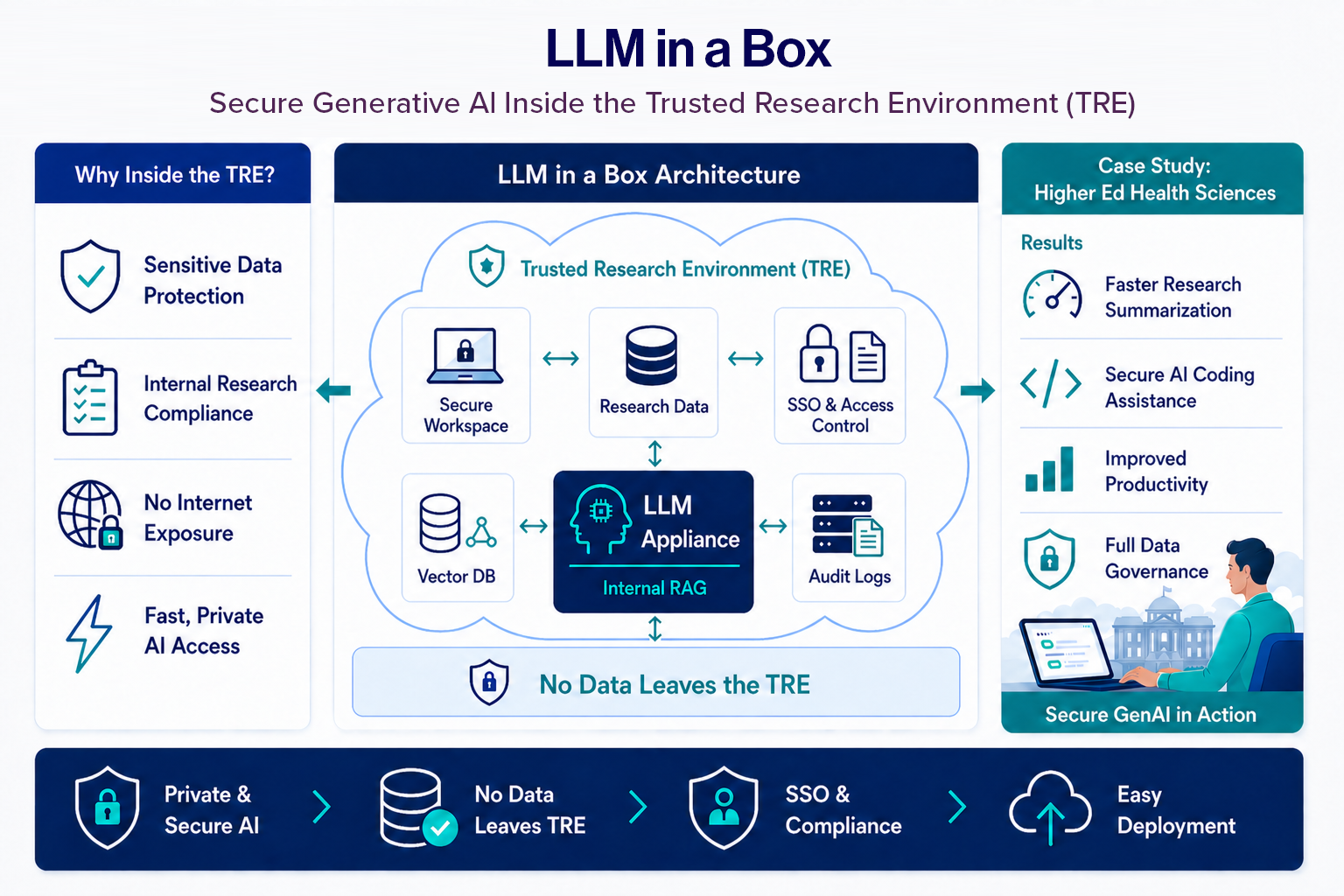
Healthcare organizations, universities, research institutes, and life sciences teams often work within Trusted Research Environments (TREs), secure digital environments designed to protect sensitive data while enabling approved research and analytics. In these environments, sending prompts, files, or research outputs to public AI services is often not permitted.
This is where a new deployment model is emerging:
LLM in a Box
A secure, private, enterprise-ready Generative AI appliance deployed directly inside the Trusted Research Environment.
The Challenge: AI Innovation vs. Data Protection
Many organizations want to empower users with Generative AI, but face common barriers:
- Sensitive data cannot leave controlled environments
- Public AI tools may not meet governance requirements
- Internal security teams require auditability and access controls
- Researchers need AI capabilities embedded into existing workflows
- IT teams need fast deployment without building a platform from scratch
The result is often delayed adoption, even when demand from users is strong.
The Solution: LLM in a Box Inside the TRE
LLM in a Box is a pre-configured private AI appliance deployed directly inside the Trusted Research Environment. Instead of relying on external AI endpoints, the models, interfaces, and supporting services run entirely within the organization’s cloud or secure network boundary.
This gives users a familiar AI experience while keeping data protected.
Typical Components Included
Core AI Runtime
- Ollama or equivalent private model runtime
- Approved open-source or enterprise LLMs
- Secure web-based chat interface
- API access for enterprise applications
- Multi-model routing options
GPU Compute Layer
- GPU-enabled infrastructure for acceleration
- CUDA / driver stack
- GPU health monitoring
- Auto start / stop scheduling for cost optimization
- Shared GPU access controls
Training & Fine-Tuning Layer
- JupyterLab workspaces
- PyTorch
- Hugging Face Transformers
- LoRA / QLoRA fine-tuning toolkits
- Experiment templates
Data Layer
- Secure storage for datasets
- Shared file systems
- Model artifact repository
- Vector database for RAG
- Data ingestion pipelines
Deployment Layer
- One-click model publishing
- Inference endpoints
- Batch jobs
- Model versioning
- Rollback support
Security & Governance
- SSO integration
- Role-based access controls
- Logging and monitoring
- Encryption
- Private networking
Why This Matters for TRE Environments
When deployed as an internal appliance, organizations gain:
Real-World Success Story: Higher Education Health Sciences Customer
One of our Higher Education Health Sciences customers recently adopted LLM in a Box to bring Generative AI into their internal Trusted Research Environment.
The Situation
The institution supports a broad mix of users including:
- Biomedical researchers
- Faculty teams
- Graduate students
- Data analysts
- Clinical research collaborators
They had growing demand for AI tools to help with:
- Literature summarization
- Research coding assistance
- Internal knowledge search
- Drafting documentation
- Productivity use cases for secure teams
However, their sensitive datasets and governed research environment meant public AI services were not an acceptable option.
Our Approach
We implemented a private LLM in a Box deployment inside their existing TRE architecture using an appliance model.
The solution was integrated with their secure access controls and made available internally through a simple browser-based interface, with optional GPU-enabled workspaces for advanced users.
What Users Can Now Do
Inside the TRE, approved users can:
- Ask natural language questions over internal documentation
- Summarize long research material
- Generate starter Python and R code for analysis workflows
- Fine-tune models using approved internal datasets
- Deploy internal assistants quickly
- Explore governed knowledge sources more efficiently
Business Outcomes
Within a short period, the institution achieved:
- Faster internal adoption of GenAI capabilities
- Strong confidence from security and governance stakeholders
- Improved researcher productivity
- Reduced shadow IT risk from unsanctioned public AI usage
- Scalable GPU-enabled AI platform for future use cases
Most importantly, they demonstrated that:
Generative AI and strong data governance can coexist.
Why Institutions Are Choosing LLM in a Box
For many organizations, the question is no longer whether to adopt Generative AI—it is how to adopt it responsibly.
LLM in a Box offers a practical middle path:
- Private deployment
- Rapid rollout
- User-friendly experience
- Enterprise controls
- GPU training capability
- Lower risk
Where This Fits Best
LLM in a Box for TREs is particularly relevant for:
- Higher Education
- Academic Medical Centers
- Healthcare Research
- Life Sciences
- Government Research Programs
- Financial Secure Analytics Environments
Looking Ahead
Today’s deployments often begin with secure chat and document assistance. Tomorrow’s roadmap can include:
- Domain-specific research copilots
- Secure coding assistants
- Workflow automation
- Multi-agent internal AI systems
- Fine-tuned institutional models
- Internal AI model factories
Organizations that start now create a secure foundation for long-term AI transformation.
Final Thought
Trusted environments were built to protect sensitive data. Now, they can also become engines of innovation.